
SQL 첫걸음 - 6장 인덱스 구조(4/6)
1. 인덱스
인덱스는 테이블에 붙여진 색인. 인덱스의 역할은 검색속도의 향상. 테이블에 인덱스가 지정되어 있으면 효율적으로 검색할 수 있으므로 WHERE로 조건이 지정된 SELECT 명령 처리 속도가 향상됨. 책의 목차나 색인이 인덱스와 비슷. 책 안에 있는 특정 부분을 찾을 때 본문을 처음부터 읽어나가기보다 목차나 색인을 참고해서 찾는 편이 효율적. 인덱스가 바로 이런 역할을 함. 인덱스의 구조도 목차나 색인과 비슷. 목차나 색인에 제목ㆍ키워드별 페이지 번호 적혀있듯, 데이터베이스의 인덱스에는 검색 시에 쓰이는 키워드와 대응하는 데이터 행의 장소가 저장되있음. 인덱스는 테이블과는 별개로 독립된 데이터베이스 객체로 작성됨. 하지만 인덱스만으론 아무런 의미가 없음. 인덱스는 테이블에 의존하는 객체. 대부분의 데이터베이스에서는 테이블을 삭제하면 인덱스도 같이 삭제됨.
2. 검색에 사용하는 알고리즘
데이터베이스의 인덱스에 쓰이는 대표적인 검색 알고리즘으로는 ‘이진 트리(binary tree)’가 있으며, 그 다음으로 ‘해시’가 유명.

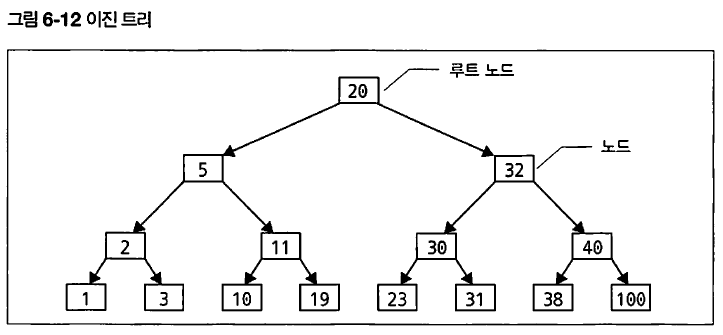
이진 트리 (binary tree)
이진 탐색은 고속으로 검색할 수 있는 탐색 방법이지만 데이터가 미리 정렬되어 있어야 함. 하지만 테이블 내의 행을 언제나 정렬된 상태로 두는 것은 힘든 작업. 일반적으로 테이블에 인덱스를 작성하면 테이블 데이터와 별개로 인덱스용 데이터가 저장장치에 만들어짐. 이때 이진 트리라는 데이터 구조로 작성됨.
 출처 : SQL 첫걸음
출처 : SQL 첫걸음
트리는 노드(node)라는 요소로 구성. 각 노드는 두개의 가지로 나뉨. 노드의 왼쪽 가지는 작은 값으로, 오른쪽 가지는 큰 값으로 나뉘어짐. 두 가지로 분기하는 구조여서 ‘이진 트리’라 불림. 검색의 진행 방법은 이진 탐새과 거의 비슷. 원하는 수치와 비교해서 더 크면 오른쪽 가지를, 작으면 왼쪽의 가지를 조사. 이진 탐색의 경우는 오른쪽의 가운데, 왼쪽의 가운데 값을 계산해야 하지만, 이진 트리에서는 구조 자체가 검색하기 쉬우므로 가지를 따라 이동하기만 하면 됨.
3. 유일성
이진 트리에서는 집합 내에 중복하는 값을 가질 수 없음. 이진 트리에서 같은 값을 가지는 노드를 여러개 만들 수 없다는 특성은 키에 대하여 유일성을 가지게 할 경우에만 유용. 그래서 기본키로 이진 트리 인덱스를 작성하는 데이터베이스가 많음.
출처 : https://smilejh.tistory.com/