
SQL 첫걸음 - 5장 그룹화(GROUP BY)(3/5)
1. GROUP BY로 그룹화
SELECT *
FROM sample51;
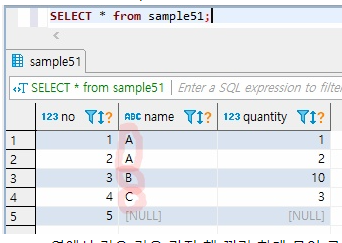
name열에서 같은 값을 가진 행 끼리 한데 묶어 그룹화한 집합을 집계함수로 넘겨줄 수 있음.
그룹으로 나눌 때에는 GROUP BY 구를 사용. GROUP BY 구에 그룹화할 열을 지정. 복수로도 지정 가능.
SELECT name
FROM sample51
GROUP BY name;
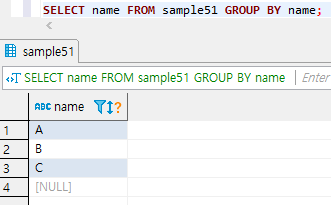
GROUP BY 구에 열을 지정하여 그룹화하면 지정된 열의 값이 같은 행이 하나의 그룹으로 묶임.
GROUP BY를 지정해 그룹화하면 DISTINCT와 같이 중복을 제거하는 효과가 있음.
그러면 DISTINCT와 무슨 차이가 있을까?
하지만 사실 GROUP BY 구를 지정하는 경우에는 집계함수와 함께 사용하지않으면 별 의미가 없음.
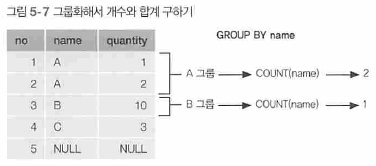
GROUP BY로 그룹화된 각각의 그룹이 하나의 집합으로서 집계함수의 인수로 넘겨지기 때문.
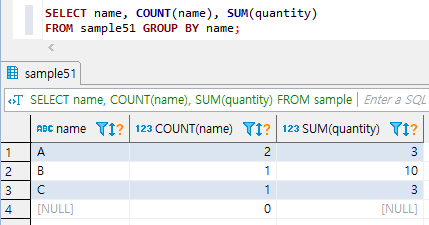
SELECT name
, COUNT(name)
, SUM(quantity)
FROM sample51
GROUP BY name;
 출처 : SQL첫걸음
출처 : SQL첫걸음
업무 환경에서 GROUP BY를 사용하는 경우는 많음.
예를 들면 각 점포별 매출실적을 집계해 어떤 점포가 매출이 올라가는지,
어떤 상품이 인기가 있지는 등을 분석할 때 사용.
여기에서 점포별, 상품별, 월별, 일별 등 특정 단위로 집계할 때 GROUP BY를 자주 사용.
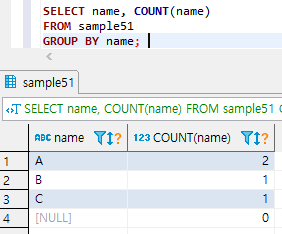
2. HAVING 구로 조건 지정
집계함수는 WHERE 구의 조건식에서는 사용 불가.
SELECT name
, COUNT(name)
FROM sample51
WHERE COUNT(name) = 1
GROUP BY name; -- 이렇게 사용불가
name열을 그룹화하여 행 개수가 하나만 존재하는 그룹을 검색하려하나 에러 발생..
–> 이유는 GROUP BY와 WHERE구의 내부 처리 순서와 관계있음.
WHERE 구로 행을 검색하는 처리가 GROUP BY로 그룹화하는 처리보다 순서상 앞서기 때문.
(SELECT 구에서 지정한 별명은 WHERE 구에서 사용할 수 없었던 것과 같은 이유)
cf) 내부 처리 순서
WHERE 구 —> GROUP BY 구 —> SELECT 구 —> ORDER BY 구
따라서, WHERE 구에서는 집계함수를 사용할 수 없다!
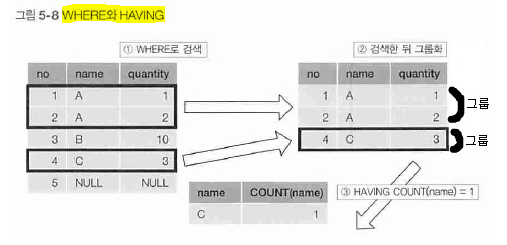
그래서, 집계한 결과에서 조건에 맞는 값을 따로 걸러내기위해 HAVING 구를 사용.
HAVING 구를 사용하면 집계함수를 사용해서 조건식을 지정할 수 있음.
HAVING 구는 GROUP BY 구의 뒤에 기술하며, WHERE구와 동일하게 조건식을 지정.
조건식에는 그룹별로 집계된 열의 값이나 집계함수의 계산결과가 전달된다고 생각하면 됨.
조건식이 참인 그룹값만 클라이언트에게 반환.
WHERE 구 와 HAVING 구가 같이 사용될 경우 ..
(결과적으로 WHERE 구와 HAVING 구에 지정된 조건으로 검색하는 2단 구조가 됨.)
 출처 : SQL 첫걸음
출처 : SQL 첫걸음
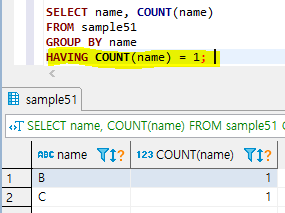
위의 에러가 발생했던 SELECT 명령을 HAVING 구를 사용하여 수정
( GROUP BY name으로 그룹화된 각각의 그룹에서 HAVING구로 COUNT(name) = 1 인 조건에 해당하는 그룹만 검색 )
1. GROUP BY name으로 그룹화하여 각 그룹의 행수를 집계(COUNT)
2. 집계한 결과에서 조건에 맞는 값을 따로 걸러내기위해 HAVING 구를 사용
SELECT name
, COUNT(name)
FROM sample51
GROUP BY name
HAVING COUNT(name) = 1;
—> 집계함수를 사용할 경우 HAVING 구로 검색조건을 지정한다!
그룹화보다도 나중에 처리되는 ORDER BY 구에서는 집계함수를 문제없이 사용 가능.
즉, ORDER BY COUNT(name)과 같이 지정 가능.
HAVING 구의 내부 처리 순서 (GROUP BY 구 다음으로 처리됨)
WHERE 구 —> GROUP BY 구 —> HAVING 구 —> SELECT 구 —> ORDER BY 구
다만 SELECT 구 보다 먼저 처리되므로 별명을 사용할 수는 없음.
예를 들어 COUNT(name)에 cn이라는 별명을 붙이면, ORDER BY 구에서는 사용할 수 있지만
GROUP BY 구나 HAVING 구에서는 사용 불가.
BUT, MySQL과 같이 융통성있게 별명 사용할수 있는 DB제품도 있음.
▼ 아래 쿼리는 MySQL에서는 실행 가능하지만 Oracle 등에서는 에러 발생.
SELECT name AS n
, COUNT(name) AS cn
FROM sample51
GROUP BY n HAVING cn = 1;
3. 복수열의 그룹화
GROUP BY를 사용할 때 주의할 점 : GROUP BY에 지정한 열 이외의 열은 집계함수를 사용하지 않은 채 SELECT 구에 지정 불가.
SELECT no (X)
, name(O)
, quantity(X)
FROM sample51
GROUP BY name;
–> name은 GORUP BY 에서 지정하므로 OK no, quantity는 지정 불가
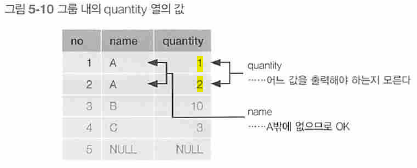
GROUP BY로 그룹화하면 반환되는 결과는 그룹당 하나의 행이 된다.
하지만 name열 값이 A인 그룹의 quantity 열 값은 1 과 2로 두개.
이때 그룹마다 하나의 값만 반환해야하므로 어느 것을 반환하면 좋을지 몰라 에러가 발생.
 출처 : SQL 첫걸음
출처 : SQL 첫걸음
이때 집계함수를 사용하면 집합은 하나의 값으로 계산되므로, 그룹마다 하나의 행을 출력할 수 있다.
즉 아래와 같이 쿼리를 작성하면 문제없이 실행 가능.
SELECT MIN(no)
, name(, SUM(quantity))
FROM sample51
GROUP BY name;
만약 no와 quantity로 그룹화한다면 (no와 quantity 두 쌍의 값이 같은 것끼리 묶는다면 )
GROUP BY no, quantity로 지정하고 이처럼 GROUP BY 에서 지정한 열이라면 SELECT구에 그대로 지정 가능.
SELECT name
, quantity
FROM sample51
GROUP BY name, quantity
4. 결괏값 정렬
GROUP BY로 그룹화해도 실행결과 순서를 정렬할 수는 없음. ORDER BY 구를 사용해 결과를 정렬.
name열로 그룹화해 합계를 구하고, 합계 내림차순으로 정렬
SELECT name
, COUNT(name)
, SUM(quantity)
FROM sample51
GROUP BY name
ORDER BY SUM(quantity) DESC
출처 : https://smilejh.tistory.com/